
OVH propose deux types de bases de données dans le cadre de ses offres d’hébergement web : les bases de données mutualisées et les bases de données privatives « SQL privées ». S’ajoute à cela un troisième type de bases, proposé dans le cadre de la nouvelle offre « Cloud Database ». Nous vous dévoilons aujourd’hui comment nous administrons ces millions de bases, en nous appuyant sur une implémentation particulière de la technologie de conteneurisation Docker.

Docker, un ami que l’on aime détester
Soyons clairs, lorsque nous avons proposé d’héberger des bases de données sous Docker, c’était la panique en interne ! Nous avons retrouvé des sysadmins en pleurs dans les couloirs, tandis que d’autres se réfugiaient sous leur bureau. Mais pourquoi Docker génère-t-il tant de craintes ?
« Docker c’est stateless, tu vas perdre toutes tes données »
Effectivement, Docker a été largement utilisé ces dernières années pour des applications dites stateless. On déploie une API et une fois que celle-ci n’est plus utilisée, on la supprime ou la relance ailleurs car elle ne dépend pas de données présentes sur le host en particulier.
Heureusement pour nous, Docker offre la possibilité d’utiliser des volumes. Un volume est un répertoire défini pour y stocker les données issues d’un conteneur et ce stockage persiste même lorsque le conteneur est supprimé.
Voici un exemple pour un conteneur MySQL. Le volume correspond au dossier /var/lib/mysql du conteneur.
/var/lib/docker/volumes/8a9f45f44164c62b6ab226ac8db6c723aaf2276749f2ec5f8e601e179e298d0e/_data/data# ls -la
-rw-r--r-- 1 - - 0 May 3 11:32 debian-10.1.flag
-rw-rw---- 1 - - 79691776 Jun 20 08:26 ibdata1
-rw-rw---- 1 - - 5242880 Jun 20 08:26 ib_logfile0
-rw-rw---- 1 - - 5242880 Jun 15 21:23 ib_logfile1
drwx------ 2 - - 4096 May 15 16:56 mysql
drwx------ 2 - - 4096 May 15 16:56 performance_schema« Avec Docker, tu vas avoir des problèmes de performance »
Nous pourrions nous lancer dans un grand discours, assorti de jolis graphiques, pour vous convaincre. Mais, à vrai dire, ce travail a déjà été fait. Voici un très bon article (en anglais), relatant différents tests effectués avec Docker et MySQL : MySQL with Docker – Performance characteristics
Ce qu’il faut en retenir : il n’existe aucune différence de performance entre une instance MySQL hébergée dans un conteneur ou hors de celui-ci. Docker n’est qu’un orchestrateur de conteneur, lequel s’appuie sur des fonctionnalités existantes du noyau Linux qui n’impliquent pas ou très peu d’overhead (consommation de ressources supplémentaires engendrée par le processus de conteneurisation).
Lors de nos propres tests, nous avons obtenu des résultats sensiblement équivalents. Alors, circulez il n’y a rien à voir ?
« Docker, ce n’est pas stable ! »
Malheureusement, c’est plutôt vrai.
Docker a fortement évolué ces dernières années, aussi bien en termes de fonctionnalités que d’architecture. Nous avions, par exemple, dans la version 1.10 un seul et unique exécutable docker qui jouait le rôle de daemon et de client. En version 1.12, vous n’avez pas moins de 7 exécutables différents.
La rapidité avec laquelle les versions de Docker s’enchaînent a du bon, puisque chaque release corrige des bugs plus ou moins critiques et perfectionne le fonctionnement global de la technologie. Le souci, c’est que chaque version est susceptible de contenir de nouveaux bugs, spécifiques à certains usages et donc longs à apparaître.
Il en va ainsi du cas du daemon Docker qui ne répond plus lorsqu’il doit gérer un trop grand nombre de commandes Docker inspect (qui permet d’être renseigné sur les caractéristiques du conteneur) ou de Docker exec (qui permet d’exécuter une commande à l’intérieur du conteneur). Vous pouvez trouver plus de détails sur cette problématique sur le GitHub Docker.
La solution pour résoudre ce problème ? Un simple strace sur le processus père de Docker. Car le strace envoie un appel système ptrace, ce qui a pour effet secondaire de libérer l’appel système qui bloque.
Mais il nous fallait une solution plus sérieuse, et exploitable à grande échelle. C’est pourquoi nous avons « fixé » une version précise de Docker, celle présentant la plus grande stabilité dans le cadre de notre usage particulier. Nous avons également dû contourner certaines difficultés. En effectuant moins de Docker inspect par exemple. Et, lorsque nous développons une fonctionnalité, il nous faut garder à l’esprit ces différentes contraintes.
« Et la securité ? »
Docker utilise les mêmes mécanismes de sécurité que de la conteneurisation standard (comme LXC) : des « namespaces » et des « control groups ».
Les namespaces permettent, entre autres, d’isoler vos processus à l’intérieur de votre conteneur. Ils ne voient pas ou ne peuvent interagir avec les autres processus de votre host ou des autres conteneurs présents sur ce même host.
Les control groups permettent quant à eux de contrôler vos ressources : limitation en RAM, en écriture sur le disque, en utilisation CPU, etc.
Il reste tout de même un point de vigilance : le daemon de Docker ne doit pas être accessible, que ce soit de l’extérieur par un utilisateur lambda, ou de l’intérieur par un utilisateur système.
Rendre accessible ce daemon, c’est rendre accessible l’ensemble de vos conteneurs et leurs données. Également, cela aurait pour fâcheuse conséquence de créer un point d’entrée dans votre host et votre infrastructure. Et introduire une faille de sécurité dans une image Docker revient inévitablement à voir cette faille multipliée par le nombre de conteneurs sur lesquels l’image est déployée. Raison pour laquelle nous utilisons nos propres images, rigoureusement contrôlées.
Vous pouvez retrouver l’ensemble des points abordés, ainsi que d’autres moyens de sécuriser vos infrastructures dans la documentation de Docker.
Pourquoi Docker est notre ami
Facilité d’administration
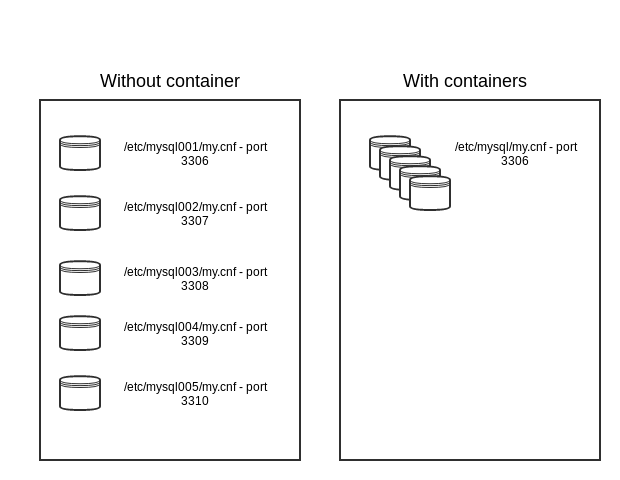
Docker garantit que notre image MySQL fonctionnera de la même manière, quel que soit le type de host et d’environnement. Ainsi, les bases de données mutualisées sont hébergées exclusivement sur des serveurs dédiés, tandis que les « SQL Privé » et « CloudDB » tournent respectivement sur des serveurs dédiés et des VM. Mais la même image Docker est utilisée.
Cette image Docker va nous permettre de configurer l’instance MySQL de manière standard. Elle écoutera sur le port 3306, et la configuration se trouvera dans le répertoire par défaut /etc/mysql/my.cnf du conteneur. Si nous voulions installer plusieurs instances MySQL sur un seul host sans conteneurisation, il nous faudrait une configuration par instance MySQL avec un port différent pour chaque instance MySQL.
Simplicité de maintenance
Dans le cas d’une mise à jour MySQL, nous sommes sûrs que si la mise à jour s’effectue correctement sur un conteneur, elle s’effectuera correctement sur l’ensemble de nos conteneurs exploitant la même image.
Les mises à jour constituent justement un point crucial, car nous savons que sans votre base de données, votre site a très peu de chance de fonctionner correctement. La procédure doit être rapide et sûre !
Voici schématisée notre procédure de mise à jour de MySQL :
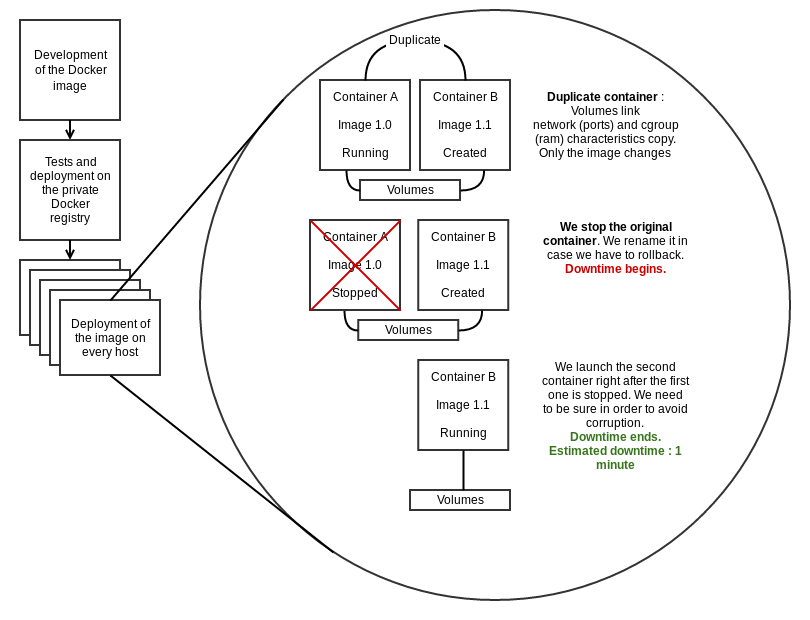
En moyenne, nous constatons un « downtime » d’une minute par conteneur. Cela correspond au temps nécessaire pour que le conteneur ferme correctement l’application qu’il héberge. Il est déconseillé de fermer trop brutalement une instance MySQL. Le risque de corruption des données existe dans ce cas, nous y reviendrons.
A noter que nous utilisons la même méthode pour déplacer un conteneur d’un host vers un autre. La seule différence étant que nous effectuons un rsync des datas avant de stopper le conteneur A, puis après avoir stoppé le conteneur A, afin de garantir la cohérence des données.
Rapidité de déploiement
Comme vous le constatez sur le schéma ci-dessus, chaque host va chercher l’image sur un registry Docker.
Pour une plus grande rapidité de déploiement, nous récupérons (docker pull) chaque image sur les hosts avant de mettre effectivement en production une nouvelle image. Il nous suffit alors de faire une simple requête HTTPS vers le daemon Docker pour lui indiquer de mettre à jour les images souhaitées, ou de déployer un nouveau conteneur basé sur la nouvelle image.
Pour résumer, il nous suffit simplement de placer notre nouvelle image sur le registry pour effectuer la mise en production. On a vu plus compliqué !
OOMKiller, la bête noire des bases de données
Nous avons été confrontés à un souci particulier avec les conteneurs : l’OOMKiller. Cette fonctionnalité kernel permet au noyau Linux de stopper (brutalement) un processus qui dépasse la capacité maximale de mémoire disponible.
Par défaut en cas de dépassement de mémoire, la fonctionnalité cgroups envoie un signal de type SIGKILL au processus du conteneur. Lorsque le processus reçoit ce type de signal, il s’arrête immédiatement sans terminer la moindre action, ce qui peut provoquer une corruption de la base de données et donc des pertes d’informations.
Nous avons expérimenté différentes solutions.
1/ Changer les capacités Linux représentées par l’option « --cap-add » lors de l’instanciation du conteneur.
docker run --detach --memory 268435456 --cap-add=SYS_RAWIOAvec cette « capacité » l’OOMKiller envoie maintenant un signal de type SIGTERM, indiquant au processus de se terminer proprement. Mais cela ne peut marcher, car le processus sature déjà 100 % de la mémoire disponible. Il ne peut donc plus allouer la mémoire nécessaire pour se terminer correctement. On se retrouve alors avec un conteneur bloqué.
2/ Désactiver l’OOMKiller grace à l’option –oom-kill-disable.
docker run --detach --memory 268435456 --oom-kill-disableDans ce cas-là, notre conteneur ne sera jamais « killed ». Cependant, il ne peut obtenir plus de mémoire. De ce fait, il devra attendre que des plages mémoire soient disponibles pour se fermer, plages qui ne seront pas libérées car utilisées par le processus. On se retrouve dans la même situation que précédemment : un conteneur bloqué.
3/ La solution choisie : un deuxième deamon dans le conteneur.
Bien que cela soit contraire aux bonnes pratiques liées à l’utilisation de conteneurs, nous avons introduit un daemon qui se charge de surveiller la mémoire utilisée et d’envoyer lui-même un signal de type SIGTERM pour que le processus se termine correctement. Pour ce faire, le daemon doit envoyer le signal avant que le processus n’utilise toute la mémoire.
Simple ? Pas vraiment ! Car le concept de la mémoire Linux est d’allouer le maximum de mémoire possible, puis de réutiliser cette mémoire : une page libre est une page perdue (« A free page is a wasted page »). On obtient vite des conteneurs qui atteignent leur limite sans toutefois la dépasser. Le daemon passe donc son temps à redémarrer les conteneurs…
C’est pour cette raison que nous avons introduit la « soft-limit. »
docker run --detach --memory 268435456 --memory-reservation 255013684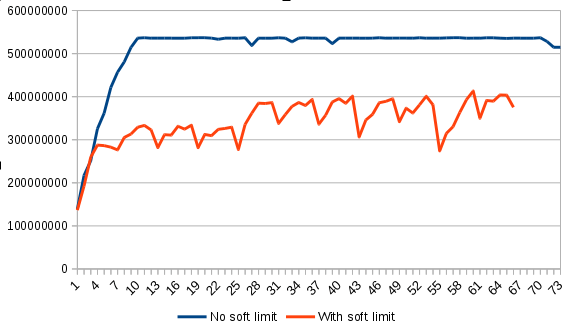
Sur ce graphique, nous pouvons constater la différence d’utilisation de la mémoire par le conteneur avec et sans soft limit. Avec la soft limit, le conteneur vide régulièrement la mémoire non utilisée.
En parallèle nous avons augmenté la mémoire des conteneurs de 5 % et fixé la soft limit 5 % en-dessous de la mémoire définie dans l’offre. Le daemon ne relancera le conteneur qu’ une fois arrivé à la limite fixée dans l’offre, 256 Mo dans notre exemple.
De ce fait, il restera 12,8 Mo disponibles au processus pour se terminer correctement. Si au bout de 60 secondes celui-ci n’a pas réussi à se terminer, le daemon envoie un SIGKILL.
Halte à la corruption
Lorsque nous avons migré l’ensemble de nos clients sur notre nouvelle infrastructure Docker, nous avions énormément d’instances MySQL avec des erreurs InnoDB, de corruption, etc.
Nous avons développé un petit outil qui se sert de toute la mécanique de Docker : « ressurect-container ».
La première étape consiste à obtenir un dump MySQL. Sans cela, nous ne pouvons aller plus loin, mais c’est également la garantie que nous récupérerons l’ensemble des données contenues dans l’instance MySQL.
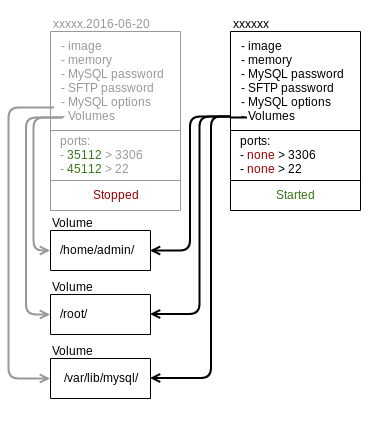
Pour ce faire, nous créons un nouveau conteneur avec les mêmes volumes que le conteneur d’origine.
Nous réparons ensuite l’ensemble des tables et effectuons un « mysql_check » de l’ensemble de l’instance.
Une fois ce dump obtenu, nous coupons l’accès réseau du conteneur et effectuons un nouveau dump afin d’obtenir des données cohérentes.
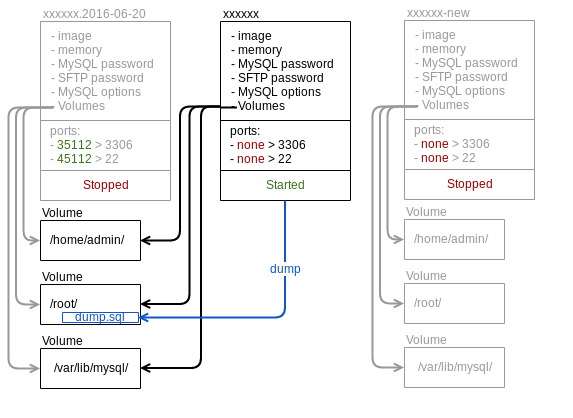
Lorsque le nouveau dump est obtenu, nous recréons un nouveau conteneur « xxxx-new » et nous insérons le dump dans la nouvelle instance MySQL vide.
L’ancien conteneur « xxxx-<date> » reste éteint quelques jours afin de pouvoir rollback sur l’opération. Il est ensuite supprimé automatiquement.
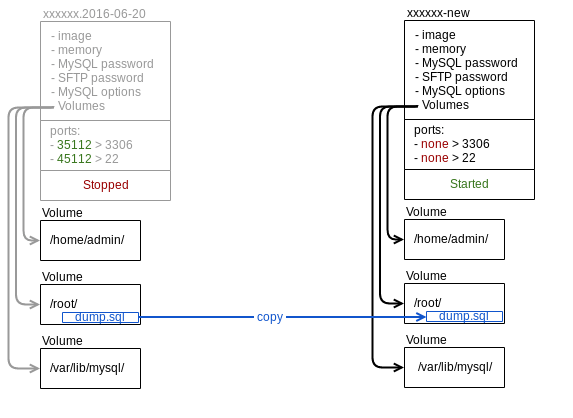
Cette procédure nous permet de réparer l’ensemble de vos tables et de corriger l’ensemble des erreurs InnoDB de votre instance (corruptions, logs dans le futurs, etc.).
IT Director
Sysadmin and developer. Crazy about R&D, new technologies and thinking outside the box.